
1500 заявок вместо 500, но отвечаем в 4 раза быстрее: кейс техподдержки Кайтен
Как техподдержка Кайтена за 4 года прошла путь от хаоса к системе: рассказывает руководитель направления

В 2022 году мы впервые рассказали, как выстроили службу поддержки в Кайтене. Собрали заявки в одном месте и перестали их терять — на тот момент это уже было большим шагом вперед. Но дальше началось самое интересное.
За 4 года поток обращений вырос почти в 3 раза — с ~500 до ~1500 заявок в месяц. Обычно в такой ситуации процессы усложняются, скорость падает, а команда начинает «тушить пожары».
Разбираемся, как у нас это получилось — вместе с Дмитрием Кирюхиным, руководителем службы поддержки в Кайтене.
Сначала было: один человек, один поток, ноль системы
Когда Кайтен только появился, отдельной службы поддержки не существовало в принципе. Обращения пользователей разбирал 1 человек: ответить, разобраться в проблеме, предложить решение — и так по кругу. Пока пользователей было немного, это работало. Но по мере роста числа пользователей становилось сложнее:
- удерживать весь контекст обращений;
- не терять запросы;
- одинаково быстро реагировать на все заявки.
А главное — система держалась на 1 человеке, а значит, масштабировать ее было практически невозможно.
Потом появилась команда
С ростом количества обращений к поддержке начали подключаться новые сотрудники. Нагрузку удалось распределить, но сам процесс от этого не стал управляемым. Заявки все также приходили из разных каналов — почты, мессенджеров, сторонних сервисов — и не собирались в одном месте. В результате:
- часть обращений терялась;
- ответы замедлялись из-за необходимости уточнять детали;
- контекст приходилось собирать заново при каждой передаче задачи.
Никто точно не знал, какая сейчас загрузка у команды и на каком этапе находится каждое конкретное обращение.
Следующим шагом стало внедрение модуля «Служба поддержки» внутри самого Кайтена
После этого заявки из разных каналов начали автоматически превращаться в карточки на единой канбан-доске.
Каждая из них стала проходить через одни и те же этапы:
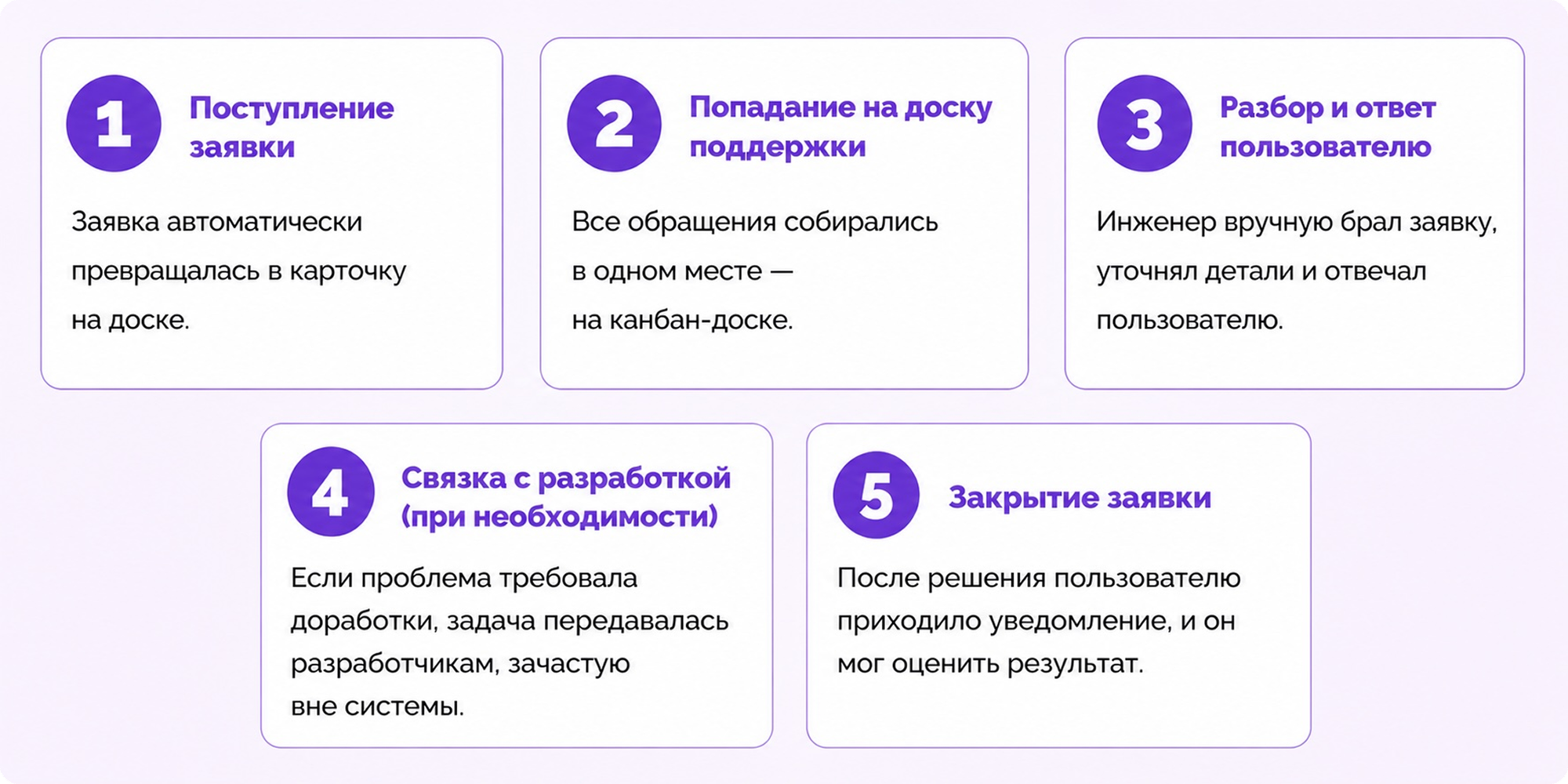
Всю работу — переписку с клиентом, внутреннюю коммуникацию, финальную фиксацию причины — мы начали вести внутри одной карточки.
Несмотря на изменения, у команды все еще было много ручной работы:
- карточки перемещали по этапам руками;
- контекст приходилось уточнять отдельно;
- статусы отслеживали без единых правил.
В итоге готовая системы для поддержки у нас была, но управляемости также не хватало: не было ни метрик, ни счетчика SLA, ни видимости узких мест.
Мы решили: пришла пора положить конец хаосу в поддержке
Раньше работа саппорта начиналась с вопроса: кто сегодня разберет очередь? В какой-то момент поймали себя на мысли, что гораздо важнее понять, почему эта очередь вообще образуется.
Поддержку перестали воспринимать как набор отдельных заявок и начали смотреть на всю систему целиком: на каких этапах появляется перегруз и где возникают задержки.
Чтобы увидеть эти закономерности, мы перестроили процесс так, чтобы его можно было измерять и анализировать.
Как новый подход выглядит изнутри
Какие изменения мы внедрили:
Сначала — научились видеть
Именно тогда в поддержке появились SLA и системная работа с метриками. А отчеты на их основе начали показывать конкретные паттерны — например, какие типы заявок стабильно выбиваются из целевого времени, что происходит с очередью в пиковые дни и где возникает перегрузка внутри команды.
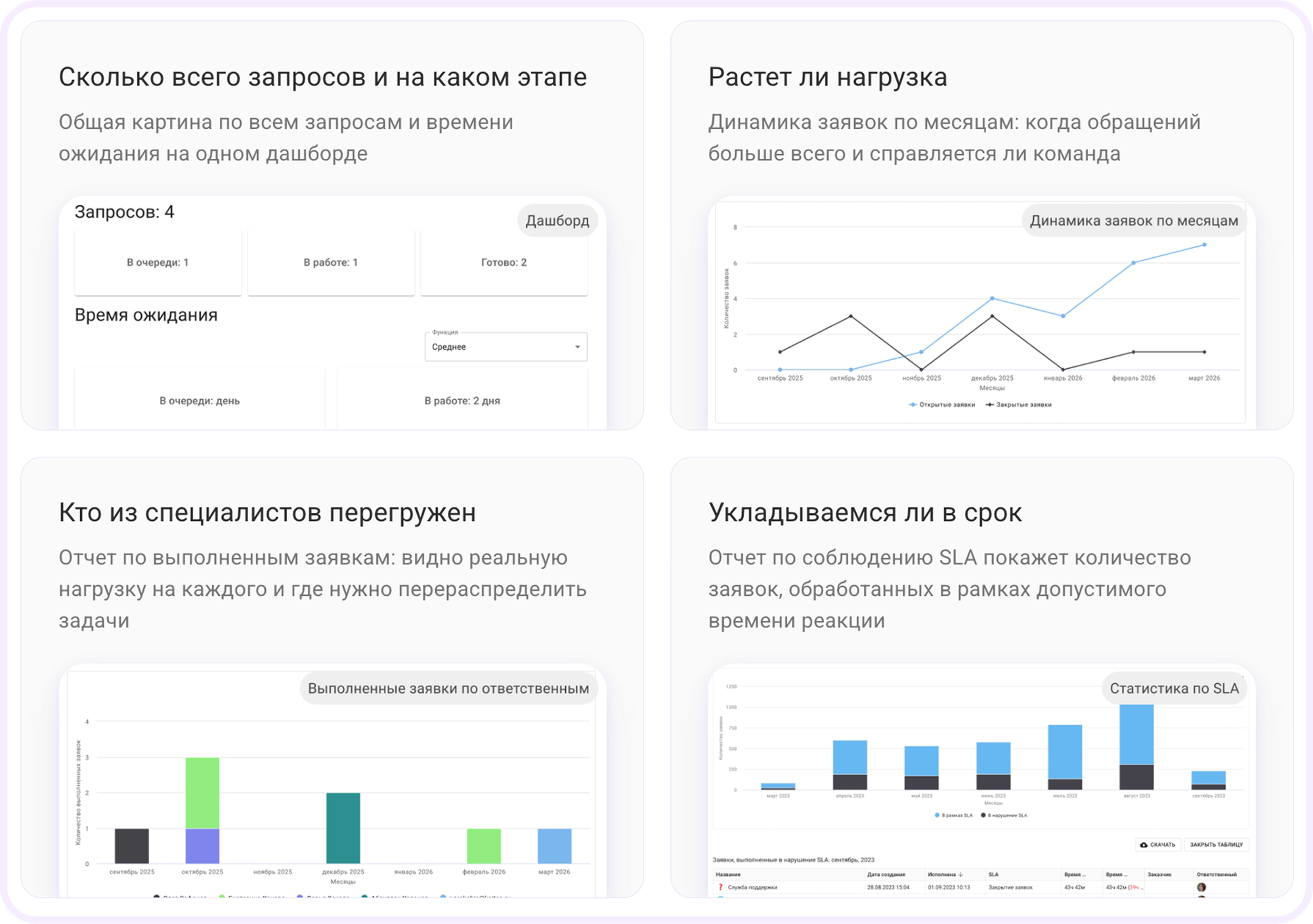
Дальше — сняли рутину с сотрудников
Мы заметили, что значительная часть времени уходит на действия, которые не требуют глубокой экспертизы: собрать контекст, распределить заявки, отследить сроки, уточнить статусы. По отдельности это 1,5-2 минуты, но в масштабе недели — 10-20 часов потраченного командного времени.
Эти операции вынесли из работы инженеров и полностью передали системе:
Идентификация клиента. Раньше разбор нового обращения начинался с базовой рутины: понять, кто пишет, какой у клиента тариф, обращался ли он в поддержку раньше. Теперь большая часть этой работы автоматизирована. При создании карточки система сама определяет клиента, а мы больше не тратим время на идентификацию.
Маршрутизация заявок. Часть обращений система распределяет автоматически — по типу и каналу входа. Ручная разборка входящих сократилась, а поток стал более предсказуемым.
SLA-таймеры. Раньше следить за дедлайнами нужно было самостоятельно — держать в голове или в отдельных напоминаниях. Сейчас таймеры отслеживает система, и при риске нарушения задача автоматически эскалируется.

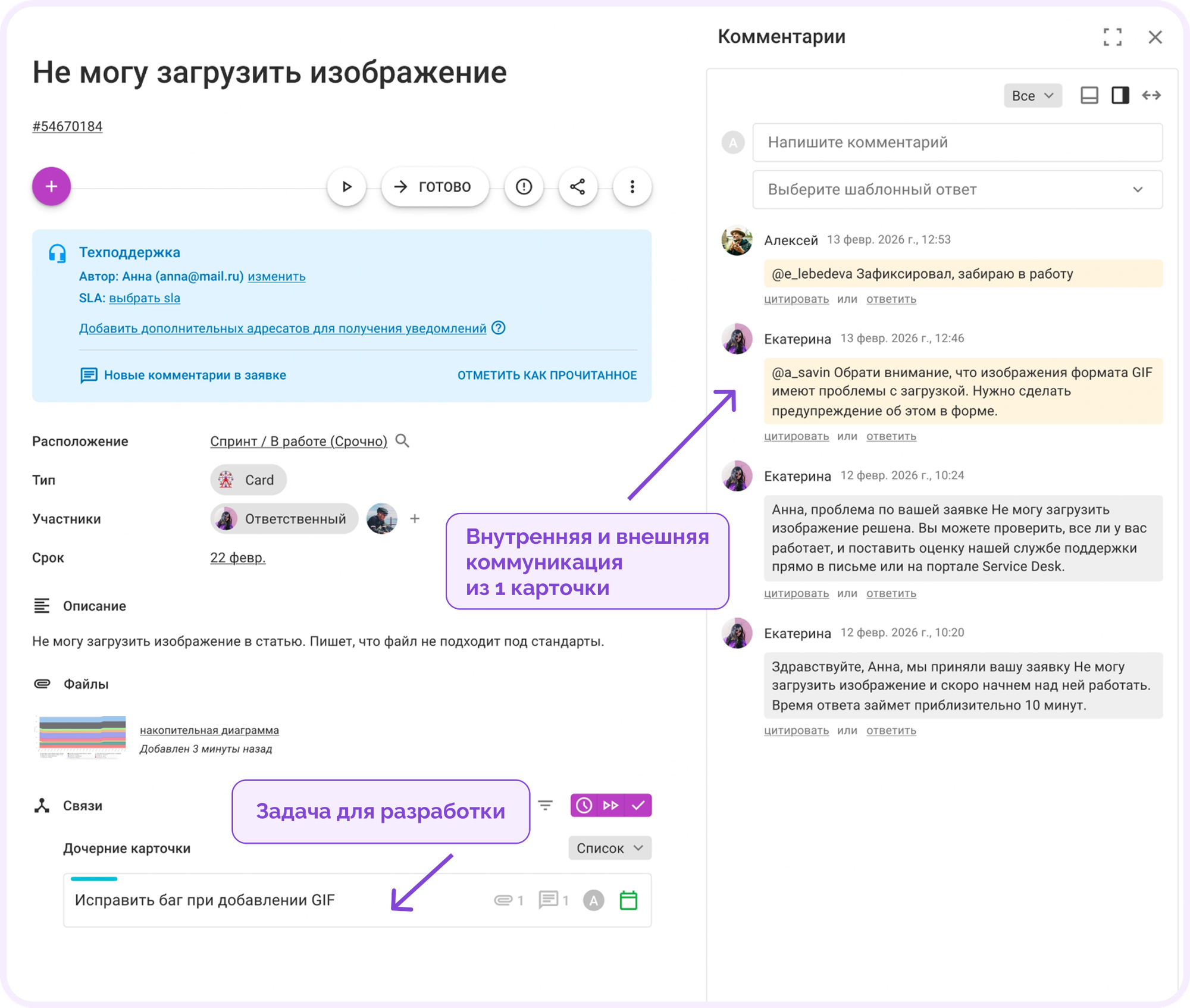
Связка с разработкой. Одно из самых заметных изменений. 4 года назад коммуникация по сложным кейсам шла через Slack: разработчики обсуждали там, поддержка ждала ответа. Как результат — постоянная рассинхронизация: в Slack одно, в трекере другое.
Сейчас тикет поддержки напрямую связан с задачей разработки внутри Кайтена. А поверх связки настроены автоматизации, которые сами двигают карточки между пространствами и колонками по событиям — например, когда разработчик берет задачу в работу, закрывает ее или выкатывает фикс. Инженеру техподдержки больше не нужно отдельно уточнять статус у разработчиков или вручную переносить карточки между этапами.
И наконец — выстроили взаимозаменяемую команду
В команде отказались от модели «один инженер — одна зона ответственности». Например, раньше один сотрудник работал только с интеграциями, а другой — с биллингом или настройками продукта. На первый взгляд удобно, на практике — рискованно. Если сотрудник уходит в отпуск или увольняется, то вместе с ним «уходит» и вся экспертиза. Поэтому заявки теперь разбираем все вместе.
А для багов работает еженедельная ротация: раз в 7 дней назначаем инженера, который ведет это направление, воспроизводит кейсы, передает в разработку. Через неделю — следующий. Каждый специалист регулярно погружается в разные зоны и держит экспертизу не точечно, а на уровне всей системы.
Так мы решили сразу несколько проблем:
- снизили риск выгорания у сотрудников;
- убрали зависимость от конкретных людей;
- выстроили стабильную команду без текучки.
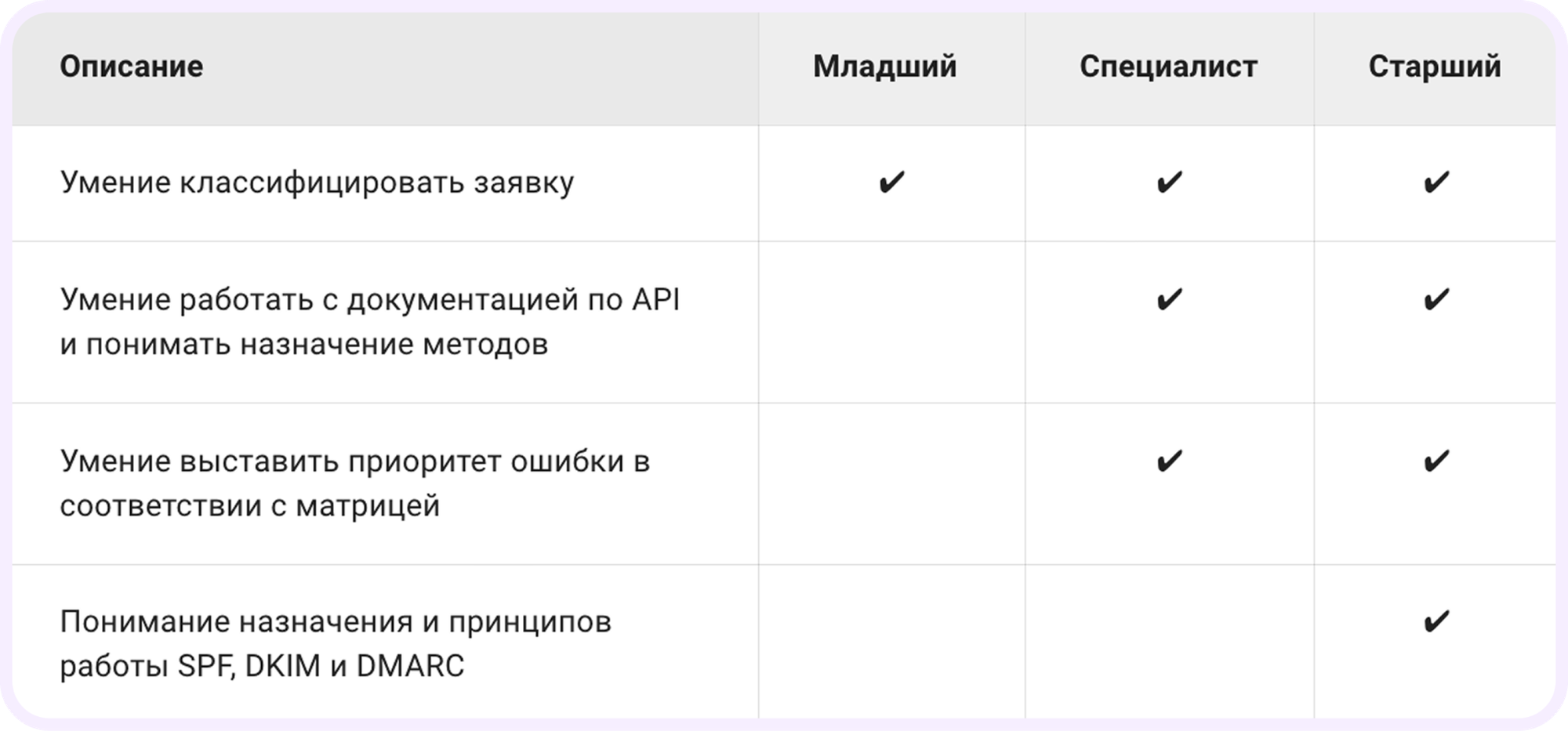
На основе накопленных данных по работе поддержки сформировали матрицу компетенций — карту навыков, где видно, что инженер закрывает уверенно, а где еще есть точки роста. Внутри — 4 направления экспертизы: работа с инструментами, продуктовые знания, техническая диагностика и работа с информацией.
Каждое направление разбили на конкретные проверяемые навыки — всего около 115 — и привязали к 3 уровням владения:
- Junior — работает по типовым сценариям и с поддержкой коллег;
- Middle — уверенно ведет задачи и разбирается в большинстве кейсов;
- Senior — берет на себя сложные и нетиповые обращения, видит системные проблемы и помогает их устранять.
Такая матрица решает сразу 2 задачи:
- рост инженеров стал прозрачным и измеримым. Не «руководитель решил», а «закрыты такие-то навыки». По этой модели в Senior уже выросли 2 инженера — это означает, что в команде стало больше специалистов, которые могут работать с любыми типами задач и поддерживать общий уровень экспертизы.
- управление взаимозаменяемостью внутри команды. Теперь мы видим, где есть риск перегрузки и какие зоны ответственности нужно планово распределять между инженерами. Матрица помогает фиксировать опыт сотрудников и превращать его в понятный план развития — где еще остаются «пустые ячейки» и каким должен быть следующий шаг.
Эффект уже заметен в ежедневной работе. Сложные кейсы реже уходят на эскалацию — Senior-инженеры сами закрывают вопросы по Enterprise-клиентам и интеграциям, берут самые тяжелые тикеты и параллельно помогают младшим коллегам быстрее расти через наставничество
Что получилось в цифрах
В 2022 году мы старались отвечать клиентам в пределах 20 минут после получения заявки. Сейчас в чате мы стабильно отвечаем за ~5 минут.
По заявкам через портал используем другую, более точную, метрику — время до типизации и приоритизации: сколько минут проходит от поступления заявки до момента, когда она разобрана и понятна по важности. В среднем на это уходит ~10 минут.

Но одна цифра не дает полной картины, поэтому мы смотрим на процентили — они показывают, как распределяется скорость обработки заявок, а не только среднее значение. Например, 15-й процентиль у нас меньше минуты. Это значит, что 15% заявок мы типизируем практически сразу
А полное решение заявки занимает в среднем ~10 часов, и каждая седьмая заявка закрывается быстрее, чем за 1 час — это также отражает 15-й процентиль. При этом показатель включает весь цикл от первого обращения до закрытия заявки, в том числе ожидание ответа от клиента и, если нужно, работу разработки. Для сравнения: в индустрии B2B SaaS среднее время полного решения — 11–24 часа.

Что оказалось неожиданно ценным в новом подходе
Первое — модуль «Служба поддержки» вышел за рамки саппорта. Через этот же модуль теперь работают и другие внутренние процессы компании: HR-запросы, административные задачи, бухгалтерия. Это стало бесплатным бонусом к внедрению — по сути, службой поддержки пользуется вся компания, хотя изначально модуль создавали именно под задачи внешней поддержки клиентов.
Второе — коллективная память. История обращений стала рабочей базой знаний. Каждая карточка фиксирует не только проблему, но и контекст: как формулировался запрос, какое решение было принято и что происходило дальше. Новому инженеру достаточно около недели, чтобы погрузиться в работу — раньше на это уходил почти месяц.
Сейчас каждый сотрудник:
- проходит по типовым кейсам своей зоны и смотрит, как они решались раньше;
- в реальных задачах может быстро найти похожее обращение и опереться на готовое решение;
- видит контекст: что именно спрашивал клиент, как формулировали ответ и какие действия предпринимали.
Так старые кейсы помогают решать новые, и новым сотрудникам не нужно каждый раз обращаться к коллегам или разбираться с нуля.
Третье — поддержка стала источником данных для принятия решений. Раньше многие выводы делались на ощущениях: «кажется, пользователи просят вот это». Сейчас любой тезис можно подтвердить данными из системы: сколько пользователей столкнулись с проблемой, в каком контексте она возникает и как меняется со временем.

Что планируем дальше
Следующий шаг — автоматизация типовых обращений с помощью ИИ, чтобы обрабатывать их без участия инженеров. Планируем автоматизировать 50% заявок: от черновиков ответов и автоматической классификации — до полноценного бота, который закрывает сценарии сам. Проект пока на стадии архитектуры.
Поддержка развивается вместе с продуктом — и становится частью его роста
За последние годы поддержка в Кайтена эволюционировала из простой канбан-доски в комплексную экосистему с глубокой аналитикой и выстроенными процессами. Даже когда объем обращений вырос в 3 раза, а команда увеличилась всего на 20%, нам удалось сохранить целевые показатели качества и скорости ответов.
Саппорт перестал быть местом, куда приходят жаловаться. Теперь это источник сигналов о том, что болит у пользователей, где продукт не работает как надо и что стоит исправить в первую очередь.
И вот главный вывод из нашего опыта для тех, кто только проходит этот путь:

Первый кейс о том, как Кайтен выстроил службу поддержки, можно посмотреть здесь. Узнать больше о модуле «Служба поддержки» — на странице продукта.
