Fail Fast: что это за принцип и как применить его в своей компании
Рассказываем, как ошибки помогают экономить и добиваться результатов

 Показать, как работает Kaiten?
Показать, как работает Kaiten?
Многие управленцы боятся провалов — кажется, что ошибка обязательно ведет к убыткам, конфликтам или потере доверия. Но в реальности неудачи — часть пути к рабочему продукту.
Чтобы найти действительно ценный и реализуемый продукт, нужно быть готовым к нескольким провалам. Поэтому важно ошибаться быстро, рано и с минимальными затратами.
Как раз про это принцип Fail Fast, работа по которому позволяет ошибаться на ранних стадиях проекта, когда ошибки еще не несут большие потери и затраты. Рассказываем, в чем он заключается, где его можно применить и какой результат он даст.
Что такое Fail Fast и для чего он нужен
Fail Fast (быстрые неудачи) — это стратегия раннего выявления ошибок и слабых гипотез. Методика позволяет не тратить ресурсы на неэффективные решения. Лучше ошибиться сразу и дешево, чем на финальных стадиях и за большие деньги.
- Быстрое выявление нерабочих решений — чтобы не тратить ресурсы на заведомо провальные идеи.
- Минимизация затрат — ошибки совершаются на дешёвых этапах, до масштабирования.
- Ускорение итераций — позволяет быстрее находить эффективные подходы.
- Повышение гибкости команды — облегчает адаптацию к новым данным и условиям.
В некоторых источниках принцип Fail Fast называют иначе — например, Fail Cheap («ошибайся дешево») или Fail Early («ошибайся рано»), но суть остается той же.
Что еще стоит знать о Fail Fast
Подход связан с Lean Startup — методологией бережливого производства. В ее основе лежит стремление максимизировать ценность при минимальных потерях. При работе по этой методологии команды используют принцип: «создать–оценить–научиться». То есть они достигают цель через непрерывное обучение, быструю обратную связь от пользователей и постепенное улучшение продукта.
Fail Fast — один из ключевых механизмов реализации этой идеи: он позволяет получать знания о том, что не работает, раньше, чем бизнес потратит значительные ресурсы на провальный процесс.
Fail Fast не равно плохо спланированная работа. Это осознанная стратегия, встроенная в процесс, а не формат «сломали — починим».
Также есть подход, который отличается от Fail Fast. Он называется Fail Safe. Их различия на примере разработки:
Когда уместно использовать принцип быстрых ошибок
Fail Fast может быть подходящим принципом в сферах:
- Разработка ПО — IT-команда находит баги на ранних этапах, а не после релиза. Также ей проще создавать нужные функциональности быстрее конкурентов, которые больше времени тратят на анализ и подготовку.
- Маркетинг — команда запускает небольшие рекламные кампании, анализирует данные и масштабируют только работающие стратегии.
- Управление проектами — руководители проверяют выполнимость задач до полного запуска.
- Стартапы — бизнес тестирует идеи через MVP, прежде чем вкладываться в полный продукт. Например, можно протестировать спрос на товар, создав несколько прототипов, а не разворачивать целое производство работающего продукта, который может не встретить спрос на рынке.
Пример: Команда запускает новый мобильный сервис доставки еды. Вместо долгой разработки полноценной версии с обширным функционалом создают минимальный продукт: базовый интерфейс и три ресторана-партнера. Через неделю анализируют данные и видят низкий спрос. Это сигнал, что концепция требует доработки или изменения.
Без подхода Fail Fast команда потратила бы месяцы и бюджет на полную версию, прежде чем обнаружить проблему. С Fail Fast удается быстро проверить гипотезу, внести коррективы или остановить неэффективный проект, сократив потери.
Как применять принцип Fail Fast в своей компании
Без опорных правил быстрые ошибки легко превращаются в бесконтрольные провалы. Чтобы подход приносил выгоду, а не убытки, важно соблюдать несколько принципов:
Поддерживайте быстрые проверки на уровне процессов. Fail Fast — это не про презентации и обсуждения одной гипотезы на десяти встречах. Это про то, чтобы проверить идею в рабочей среде за считанные дни. Чтобы это стало возможным, уберите лишние согласования, сделайте «выкатывание» функций простым, а замер — автоматическим. Чем меньше преград на пути от гипотезы до результата, тем больше вы успеете проверить.
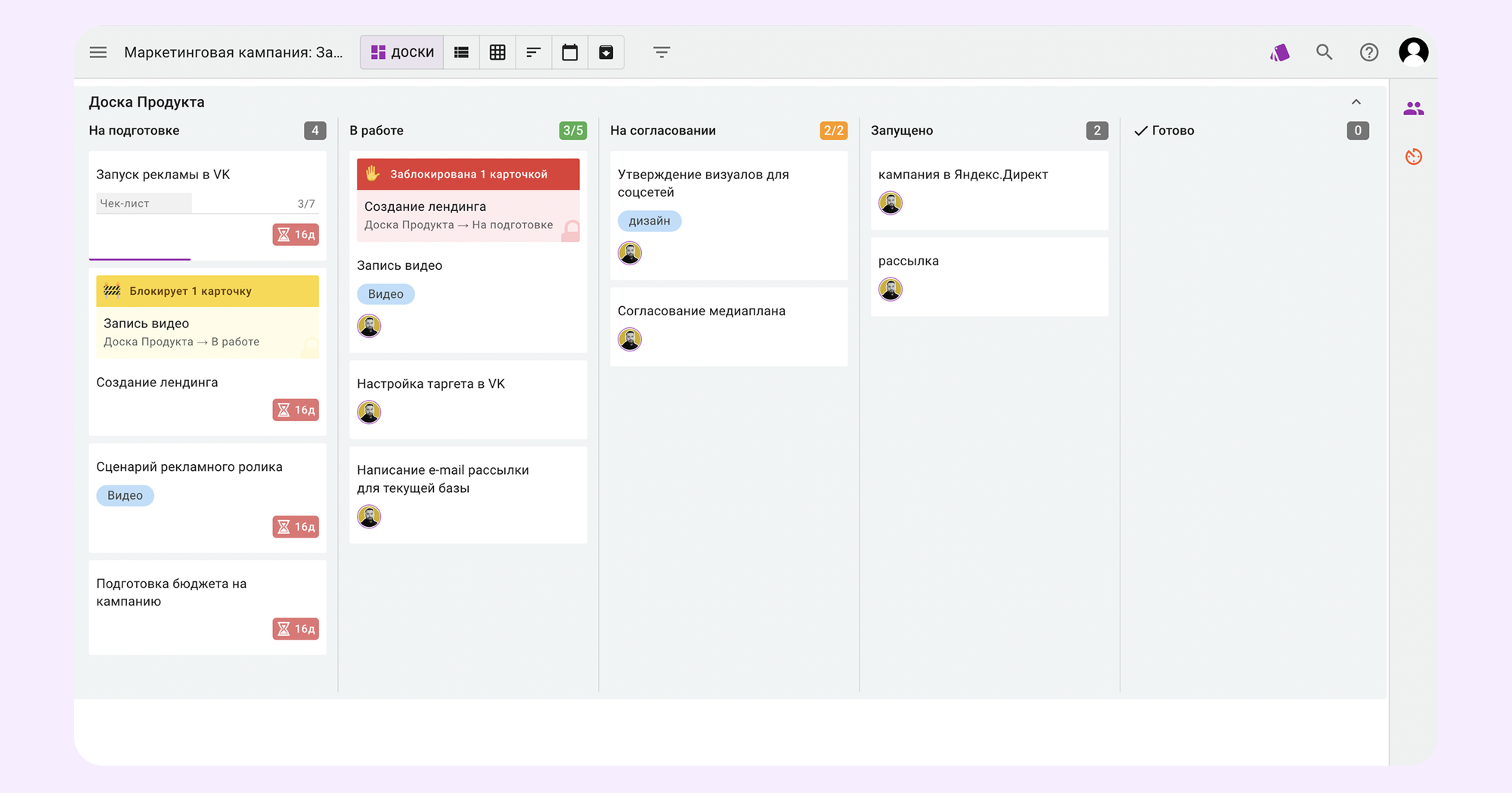
Например, Kaiten. Решение помогает сделать рабочий процесс прозрачным: вы сразу видите, где гипотеза «застряла», кто над ней работает и какие задачи уже провалены или требуют переоценки. Это ускоряет не только итерации, но и принятие решений по ходу эксперимента.
Определяйте критерии остановки заранее. Когда команда запускает новую функциональность, продукт или что-то другое, должно быть понятно, при каких условиях прекратить работу. Без четкой точки отказа легко начать дорабатывать, добавлять, объяснять результаты — вместо того чтобы принять решение. Простой вопрос помогает: «Что должно произойти, чтобы мы поняли — идея не сработала?»
Проверяйте в боевых условиях. Надежные сигналы появляются только при работе с реальными пользователями. Поэтому внутренние тесты — это подготовка, но не полноценная замена реальных условий. Запускайте изменения сначала на ограниченную аудиторию — например, новую модель продаж в одном регионе.
Упростите «откат». В первую очередь это актуально для IT-команд. Если вернуть систему в исходное состояние сложно — экспериментировать становится дорого. Инфраструктура должна поддерживать обратные шаги: откат кода, остановка функциональности, отключение метрик. Это не перестраховка, а способ освободить команду от страха ошибки.
Не закрепляйте неудачные решения. Иногда сложно признать, что гипотеза не сработала. Особенно если уже вложено время, ресурсы, обсуждения. Но затягивание обходится дороже. Чем раньше команда остановится, тем больше у нее останется времени на следующее решение. Это и есть суть подхода: не избегать ошибок, а вовремя их видеть и делать выводы.
Риски при работе по принципу Fail Fast
Некоторые из них:
Напряжение в команде. Если один из основных участников экосистемы часто вносит изменения в продукт или полностью его переделывает, следуя подходу быстрых решений и проб, это может привести к убыткам у партнеров. Такие разные взгляды на работу с продуктом могут вызывать напряженность и конфликты между сторонами.
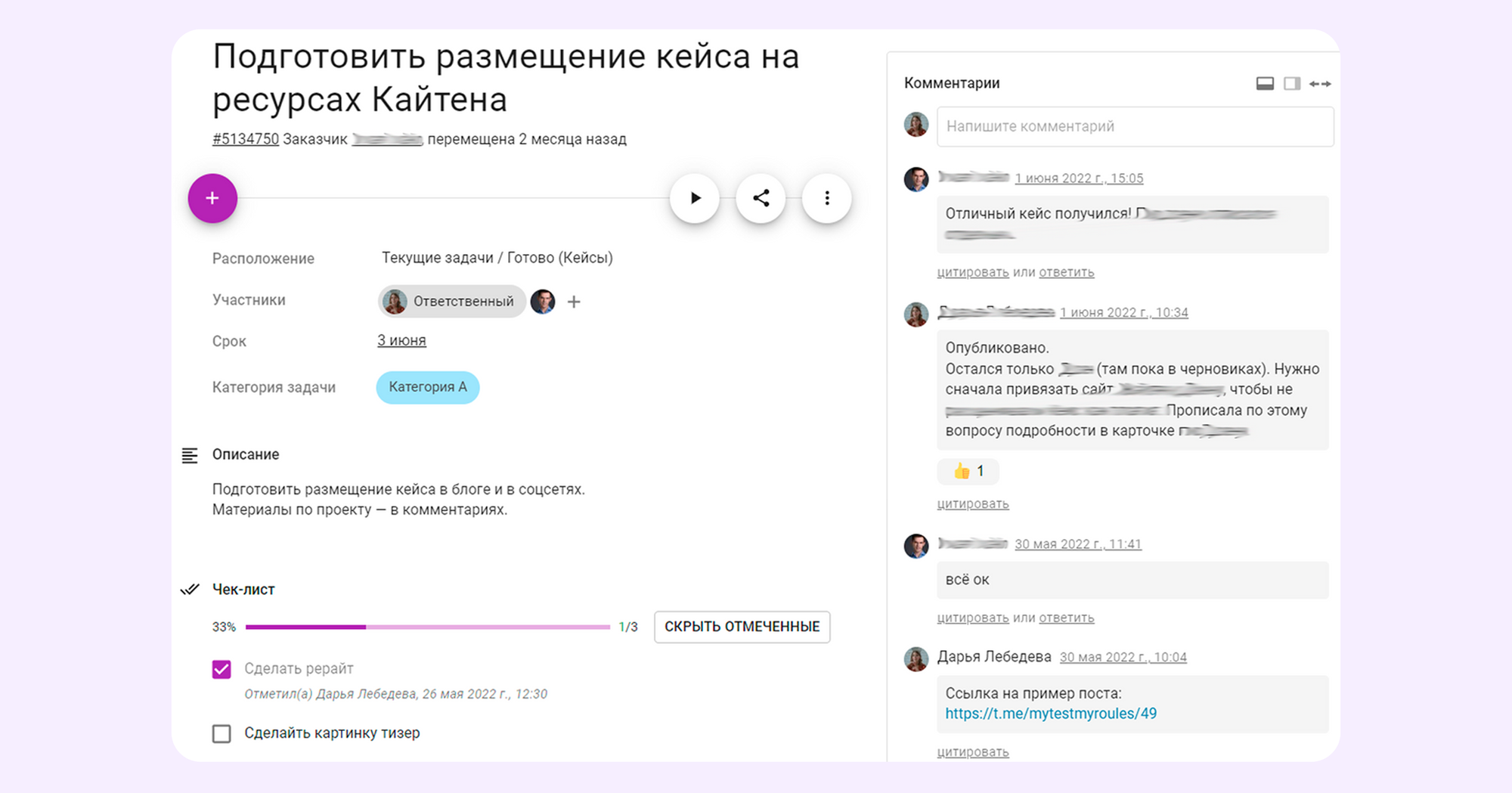
В Kaiten для этого помимо канбан-досок есть детализированные карточки. Внутри каждой можно переписываться с коллегами, добавлять кастомные метки, сроки и фиксировать результаты. Все это доступно на бесплатном тарифе:
Страх со стороны команды. Есть сотрудники, которые живут по принципу «делай хорошо, а плохо не делай». То есть для них успешной работой считается та, где нет ошибок. Для таких сотрудников Fail Fast может стать источником сомнений — из-за ошибок может казаться, что вот-вот и сделают выговор, сократят зарплату или вообще уволят.
Поверхностный анализ. Стремление быстро перейти к новой идее мешает глубокому изучению причин неудачи, из-за чего ошибки продолжают повторяться. Из-за этого уменьшается вероятность довести до успеха изначально перспективную, но требующую доработки идею.
Fail Fast как принцип получения обратной связи
Короткий цикл обратной связи — одно из главных преимуществ принципа быстрых ошибок. Продукт или гипотеза быстро получают реакцию пользователей, поэтому бизнесу дешевле и проще внести изменения. Fail Fast превращает обратную связь в инструмент для быстрой корректировки курса.
Как это работает:
- HADI-циклы (Hypothesis Action Data Insights/ гипотеза → действие → анализ → итерация) позволяют быстро проверять предположения. Например, компания выдвигает гипотезу: «Клиенты чаще покупают с кнопкой “Купить в 1 клик”». Запускают тест на части аудитории, собирают данные и уже через неделю понимают, работает ли идея.
- A/B-тесты сравнивают две версии продукта, чтобы определить лучшую. Например, интернет-магазин тестирует два варианта главной страницы и через несколько дней видит, какой приносит больше конверсий.
Как контролировать работу по принципу Fail Fast возможным
Рассказываем, как ускорить обратную связь с помощью подходов IT-команд и не только:
CI/CD‑пайплайн с автоматическими тестами и откатами. Разработчики используют CI/CD — систему, которая проверяет каждое изменение автоматически. Тесты запускаются сразу, еще до того, как код попадет в продукт. Если что-то не работает, сборка останавливается. Если ошибка уходит в релиз — есть кнопка «откатить».
→ Как это может выглядеть вне разработки:
Внедряя инициативу, можно ввести аналог чек-листа запуска. Например, проверка ресурсов, сроков, доступных данных. Автоматизируется здесь не ПО, а стандарт: перед стартом команда проходит по списку, чтобы убедиться, что все готово. А если что-то пошло не так — есть способ быстро остановить, без лишних объяснений.
Feature Flags и Canary‑релизы для безопасного релиза гипотез. Feature Flags — это переключатели, которые позволяют включать или выключать новую функцию без релиза. Canary-релиз — это релиз обновлений на часть аудитории: сначала на 1%, потом на бОльшие сегменты и, если все стабильно, на всю аудиторию.
→ Как это может выглядеть вне разработки:
Допустим, вы меняете процесс работы с клиентами. Вместо того чтобы менять все сразу, попробуйте на одной команде или одном регионе. Это и есть управленческий canary-релиз. Feature Flag — когда новый процесс уже есть, но пока не включен везде. Можно включить на время, посмотреть реакцию системы и клиентов, собрать данные и выключить, если что-то не так.
Shift-left и тесты на входе. Shift-left означает: тестировать как можно раньше, еще до сборки. В разработке это unit- и contract‑тесты, которые проверяют отдельные куски системы. Если что-то не стыкуется — команда узнает об этом сразу.
→ Как это может выглядеть вне разработки:
До запуска инициативы можно проверить ключевые допущения. Например, короткое исследование рынка, пара глубинных интервью, быстрый расчет юнит-экономики. Это и есть «тесты на входе». Если идея не выдерживает проверки на старте — не обязательно вести ее дальше. Это не отказ, а экономия времени.
Observability-стек. В разработке важно не просто увидеть, что система перестала работать, а быстро понять, почему. Для этого IT-команда использует набор инструментов:
- Метрики показывают, что что-то изменилось: например, сервер долго отвечает.
- Логи дают подробности, что именно происходило в этот момент;
- Трассировка позволяет отследить путь запроса через все сервисы;
- Алерты срабатывают, когда показатели выходят за допустимые границы.
Это помогает не тратить часы на выяснение «почему все упало», а быстро найти и устранить причину.
→ Как это может выглядеть вне разработки:
Важно не просто замерять конечный результат, а видеть всю картину. Если гипотеза не дает эффекта — вопрос не только «работает или нет», но и «на каком этапе все застопорилось». Когда вы видите, где именно тормозит процесс, обратная связь приходит быстрее, а действия становятся точнее.
Что такое Fail Fast: кратко
- Fail Fast — это стратегия раннего выявления неудачных гипотез, чтобы не тратить ресурсы на неработающие идеи. Ошибки совершаются быстро и дешево, до масштабирования неработающих гипотез. Такой подход помогает ускорить итерации, повышает гибкость команд и экономит ресурсы компании.
- Принцип работает в стартапах, IT-разработке, маркетинге и управлении. Он помогает проверить идею в минимальном масштабе, прежде чем тратить ресурсы. Чем раньше понятна ошибка — тем меньше потери.
- Чтобы применить Fail Fast, нужно убрать бюрократию, заранее задавать критерии отказа и проводить проверки в боевых условиях. Обязательно — возможность быстро откатить изменения. Главное — не бояться остановиться, если гипотеза не сработала.
- Для работы по принципу быстрых ошибок разработчики применяют CI/CD, фичефлаги, canary-релизы, shift-left и observability-стек — все сокращает последствия ошибки. Аналогичные подходы можно внедрять и вне разработки.
